グラフのパーソナライズ探索とは
インデックスに基づく高速で自由なランダムウォーク解析 @ tullys
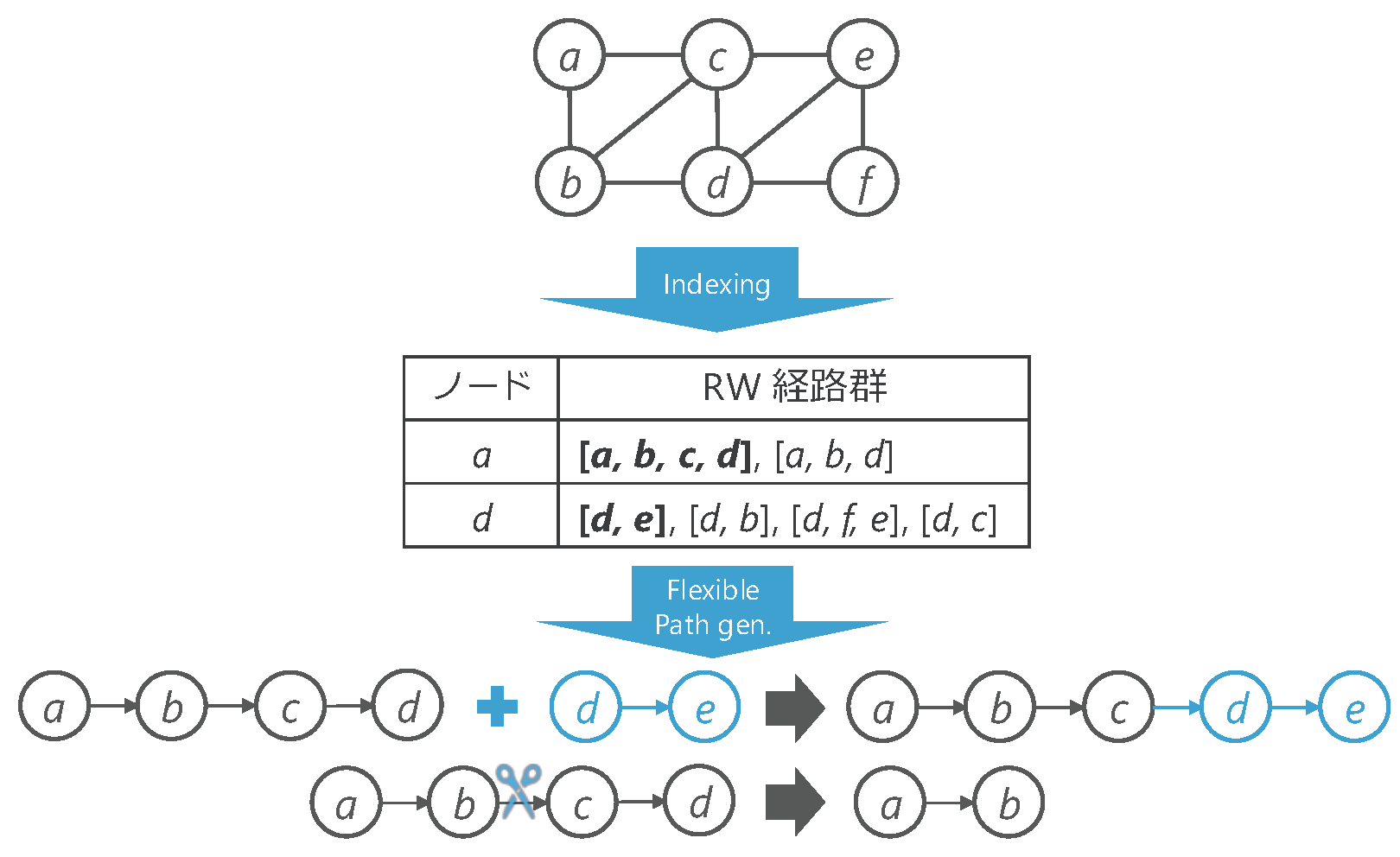
ランダムウォークを用いたグラフ解析では,経路長を制御するパラメータによって解析の特性を変化させられることが知られています.また,ランダムウォークの実行は処理のボトルネックになりやすいため事前演算によりインデックスされた経路を用いた高速化が有用です.しかし,インデックスされた経路ではその長さが固定化されるため,自由な解析が妨げられてしまいます.そこで本研究では,数学的な確率制御に基づきながらインデックスされたランダムウォーク経路同士を連結・切断することで高速かつ自由なグラフ解析を実現します.
コミュニティ検出法のランダム性を用いた重複あり小規模コミュニティ提案 @ mitsua
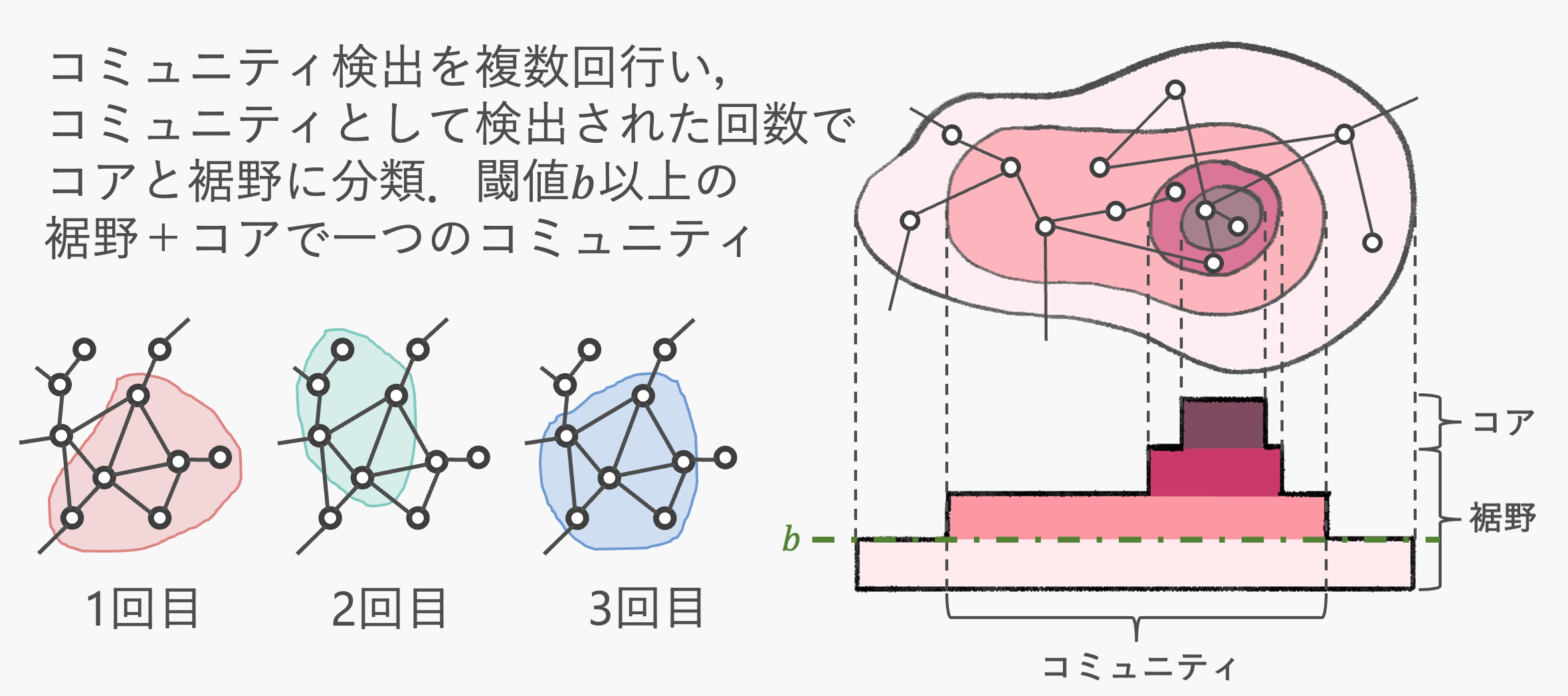
グラフを用いた興味関心の探索にはしばしば重複ありのコミュニティ検出が用いられますが,既存手法ではコミュニティへの所属度が低いノードはコミュニティに含まれないケースがあり,1ノードあたりのコミュニティ所属数が減ってしまいます.そこで,グラフの分割手法であるk-means++法とLouvain法によって複数回パーティショニングを行い,検出ノードが変化しない部分を「コア」,コアを内包し閾値となる回数以上コミュニティに所属していたノード群を「裾野」と定義し,コアを裾野によって広げることで,既存手法よりも多くのコミュニティを検出します.
ランダムウォークの類似性に基づくクラスタリング @ esty
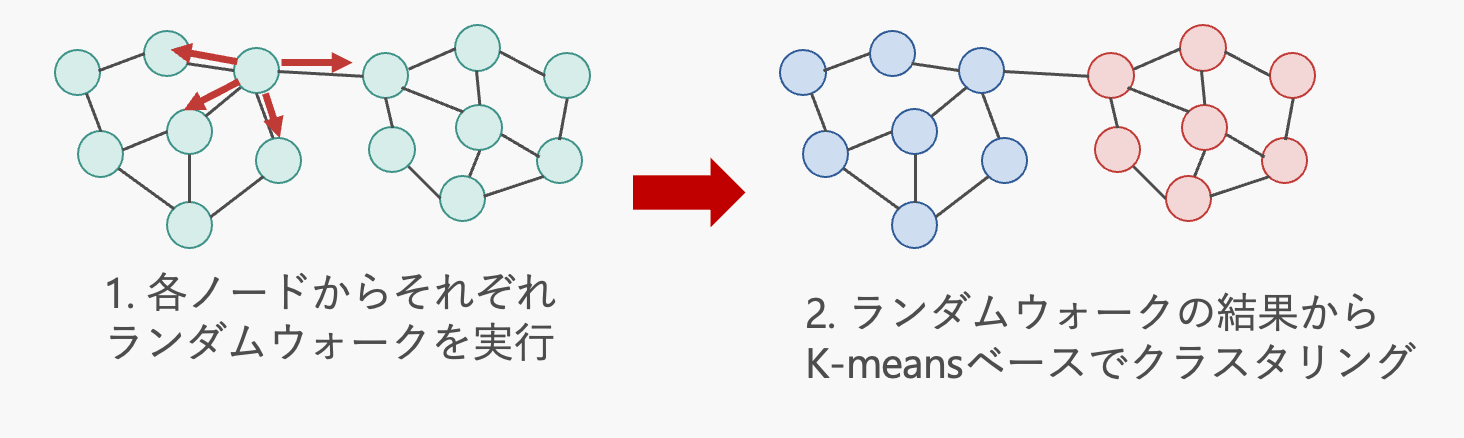
SNSなどの実世界グラフの解析において, 類似した特徴を持つノード群を検出するノードクラスタリングは有用です. 既存のクラスタリング手法では, ノードやエッジの密度に注目する方法などがありますが, 本研究では各ノードの特徴をランダムウォークによって分析し, その結果をK-meansベースの手法によってクラスタリングします. これにより, 既存手法では検出が困難な, 特徴が類似したノードを発見することを実現します.
グラフの始点近傍に基づくランダムウォーク再利用 @ stkn
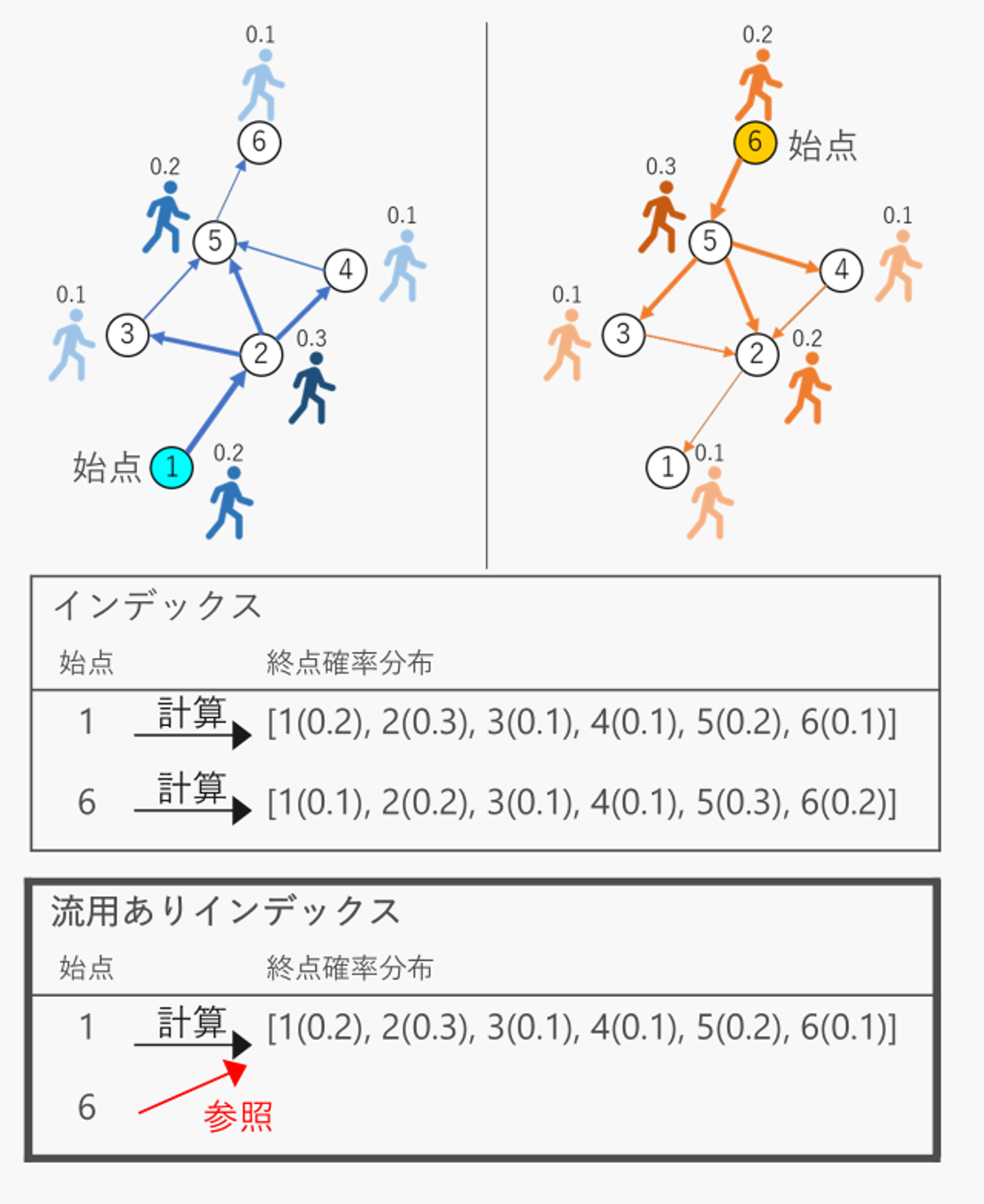
ランダムウォークを用いたグラフ解析において, ランダムウォークは大量に実行する必要があるため, 解析結果を得るには時間が掛かります. そこでランダムウォークを事前演算によりインデックスしておき, 解析時に利用することが高速化に有用です. 一方で, インデックスを保持するための空間計算量が課題となります. ランダムウォークの始点に対する終点分布を解析に用いる場合, 終点分布が類似する始点間でインデックスを流用することで, 演算精度を保ちながら空間計算量を削減することができます.