What is graph analysis?
High-speed and free index-based random walk analysis @ tullys
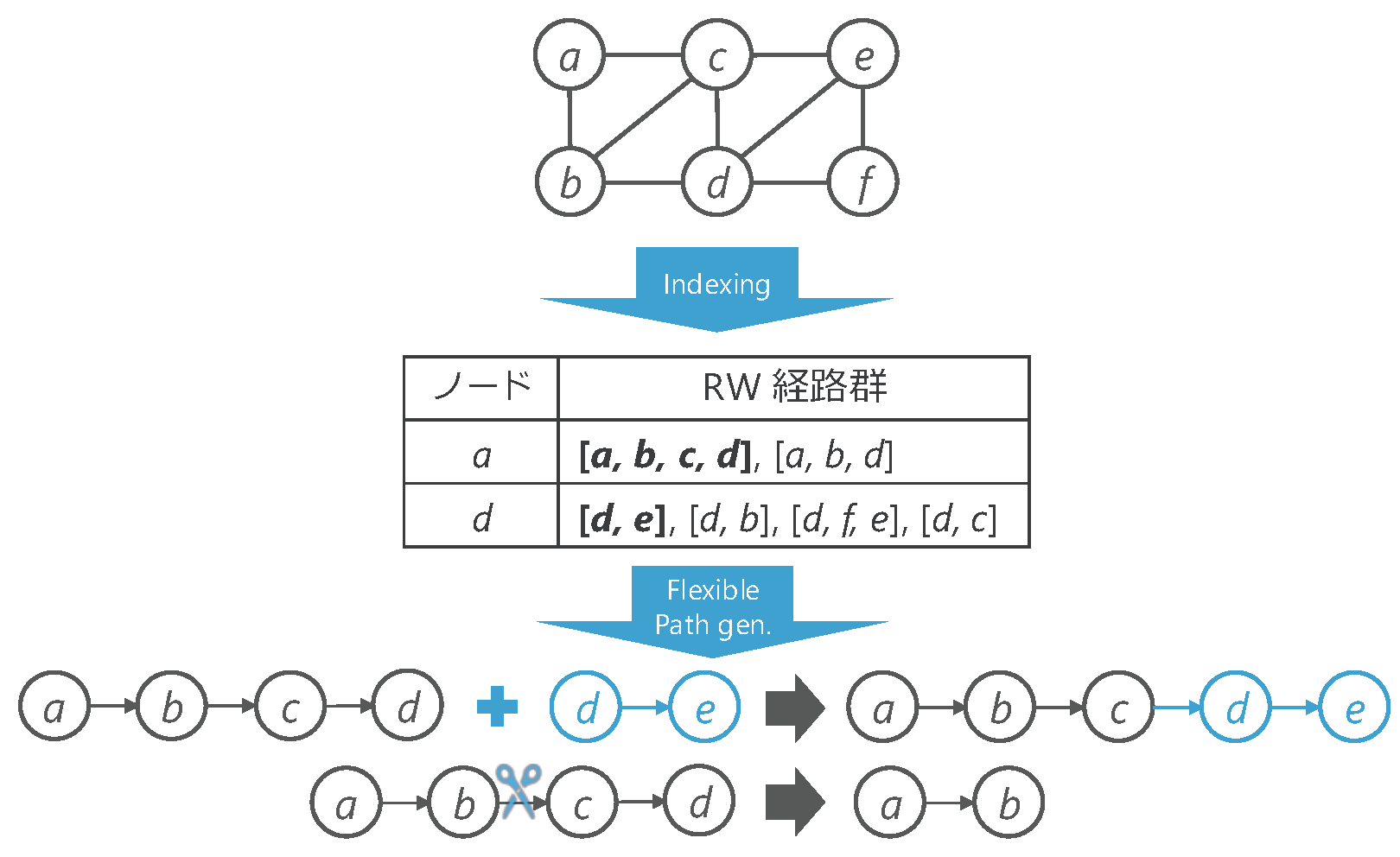
In graph analysis using random walks, it is known that the characteristics of the analysis can be altered by parameters controlling the path length. Furthermore, since executing random walks tends to become a processing bottleneck, acceleration using precomputed indexed paths is useful. However, indexed paths have fixed lengths, hindering flexible analysis. Therefore, this research achieves fast and flexible graph analysis by connecting and disconnecting indexed random walk paths based on mathematical probability control.
Small-Scale Communities with Overlap Using Randomness in Community Detection Methods @ mitsua
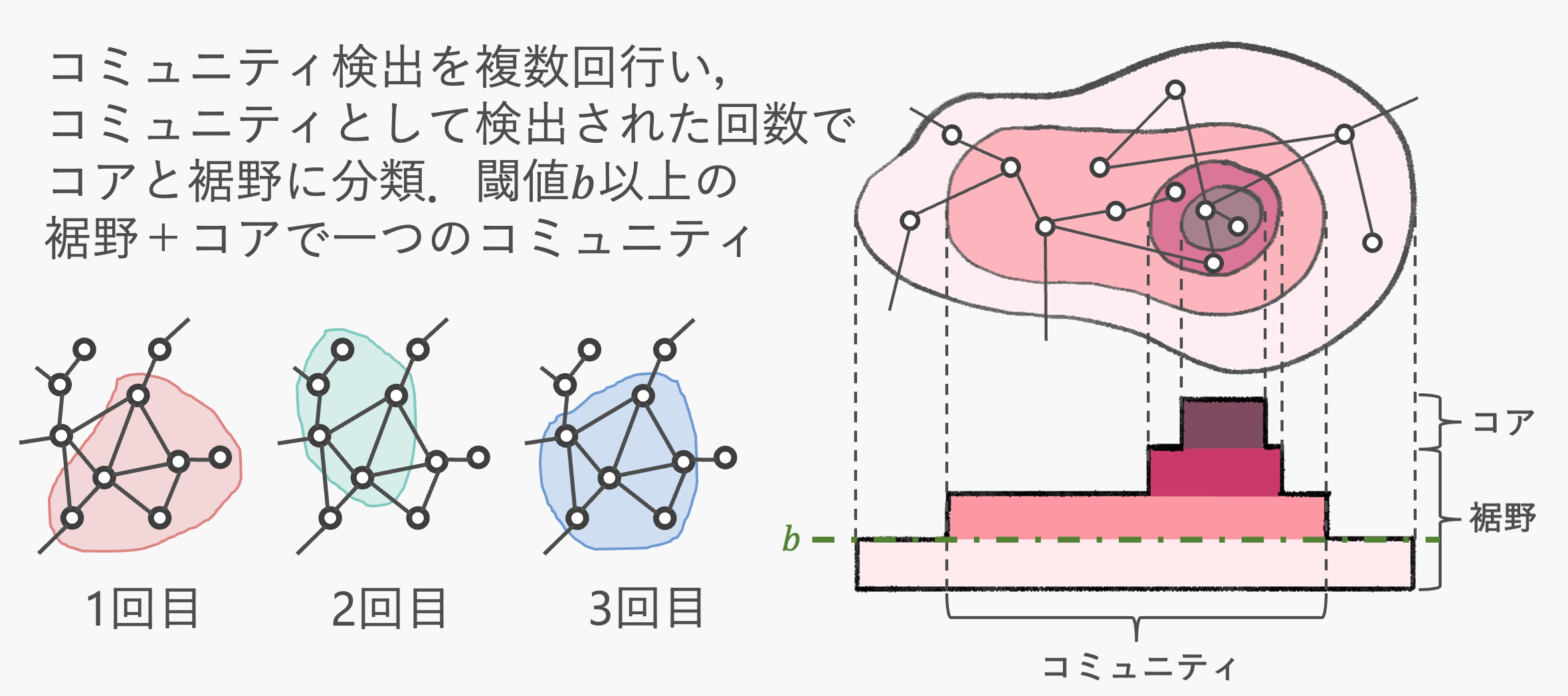
Community detection with overlapping members is often used for exploring interests and preferences using graphs. However, existing methods sometimes exclude nodes with low community membership scores, reducing the number of communities per node. Therefore, we perform multiple partitions using the k-means++ and Louvain graph partitioning methods. We define the unchanged nodes as the “core” and the nodes belonging to at least the threshold number of communities encompassing the core as the “periphery.” By expanding the core using the periphery, we detect more communities than existing methods.
Clustering Based on Random Walk Similarity @ esty
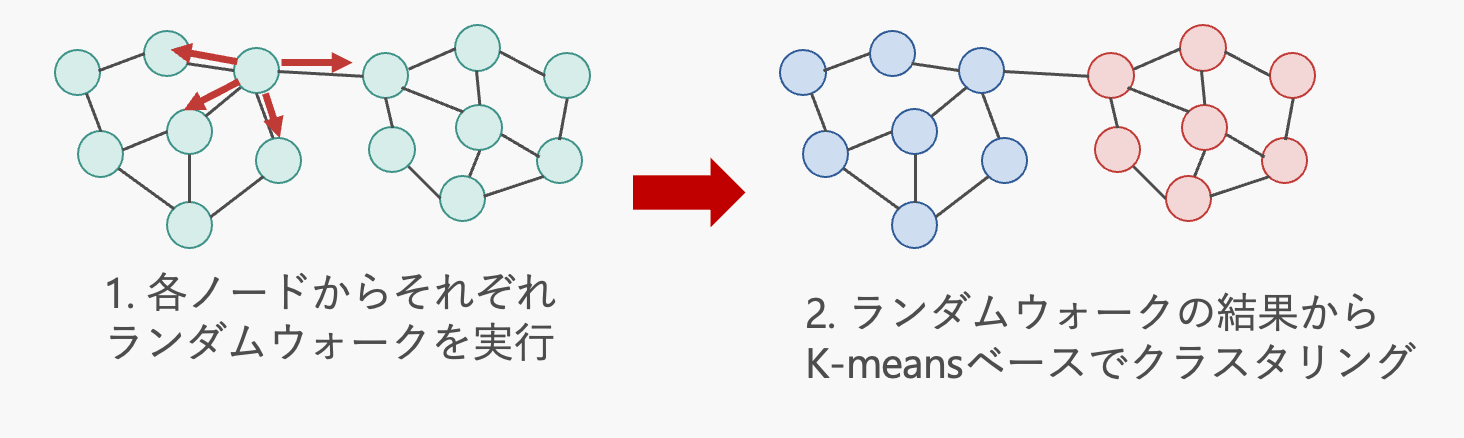
In analyzing real-world graphs such as social networks, node clustering is useful for detecting groups of nodes with similar characteristics. Existing clustering methods focus on node or edge density, but this research analyzes each node’s characteristics using random walks and clusters the results using a K-means-based approach. This enables the discovery of nodes with similar features that are difficult to detect using existing methods.
Reuse of Random Walks Based on the Graph’s Starting Point Vicinity @ stkn
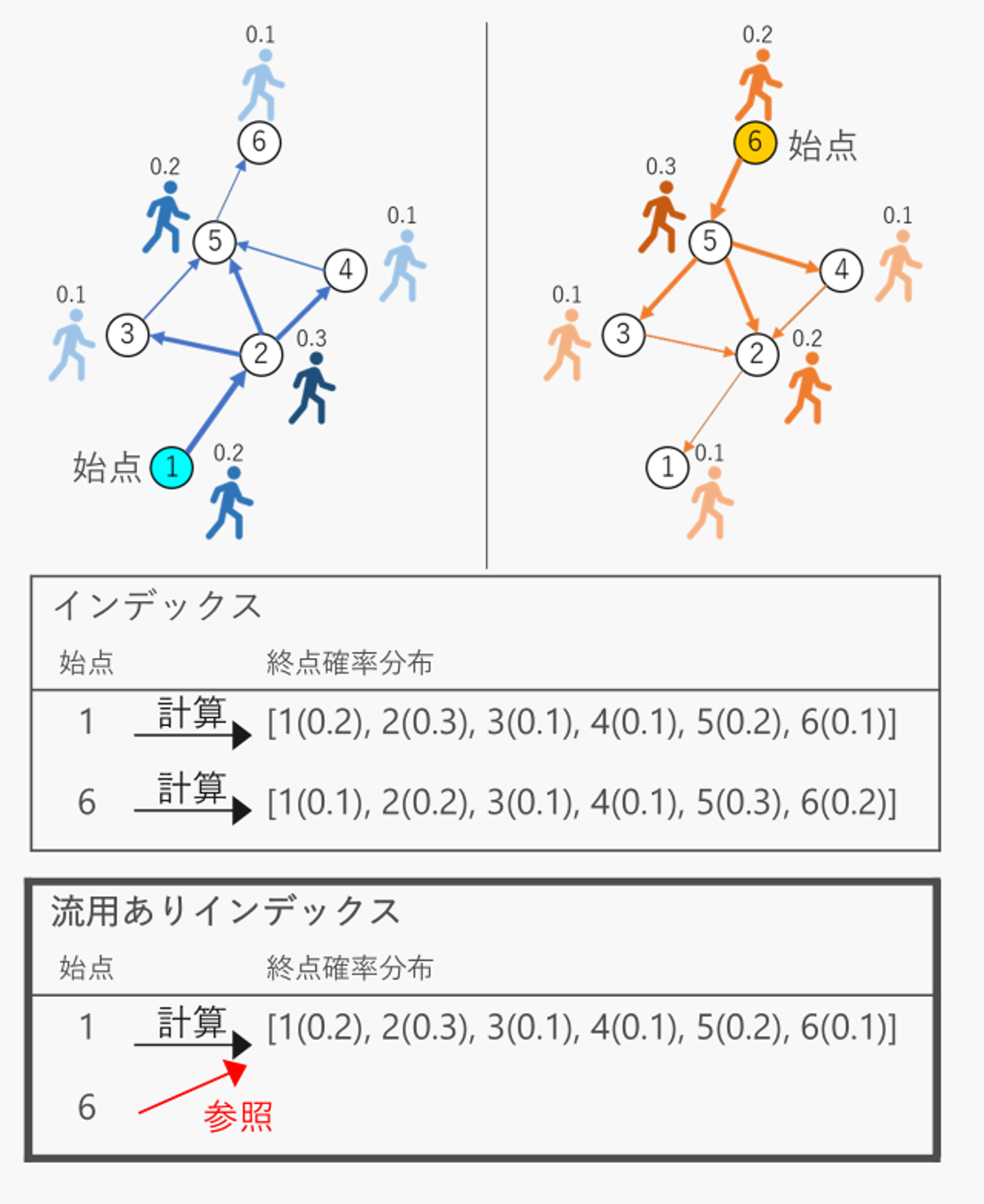
In graph analysis using random walks, obtaining results takes time because a large number of random walks must be executed. Therefore, precomputing and indexing random walks for use during analysis is useful for speeding up the process. However, the computational space required to maintain these indexes poses a challenge. When analyzing the distribution of endpoints relative to starting points, reusing indexes between starting points with similar endpoint distributions can reduce computational space while maintaining computational accuracy.